5.1 大数据报表
背景
随着在应用系统中数据的不断积累,很多业务场景中的报表会涉及到几万甚至几十万的数据量。这样数据量的报表如果使用JDBC连接一次性全部获取数据,必然造成内存不足或者溢出
UniEAP Report中已有“分段取数”来应对这种情况,将数据按照固定的行区间分段(比如每段一万条数据),每次取得一段数据来生成报表,虽然提升了报表展现时的用户体验,但是存在诸多不足:
- 总页数计算不准确
- 展现和导出时,数据段与段之间存在半页数据
- 分组报表同一组在前后两段数据中重复出现
- 对于行变列的场景,可能出现报表显示应该同一行的数据在段间被拆分成2行,出现数据完整性问题
方案简述
原“按段取数”方案存在的主要问题是:
- 不能精确计算总页数
- 导出、打印没有利用数据分段优势,导致当机
- 无法灵活控制数据截断位置,导致数据显示问题(分组完整性以及行完整性)
为了解决上述问题,提出了柔性分段方案:
识别海量数据报表的特征,不同特征的报表采用不同的分段计算方式,动态计算数据分段位置。
不求所有特性对各种海量数据报表通用。
支持的报表类型:
- 列表式报表
- 分组报表
- 交叉报表
使用规则(非常重要)
支持报表类型
海量数据报表是为了解决报表数据量很大情况下内存占用过大问题,有一定的针对性,并不是UniEAP Report内可以定义的所有报表都支持该方法,支持的报表类型为:
- 列表式报表
- 分组报表(包含分组统计)
- 交叉报表(主要针对行转列式的交叉表)
超出本范围的报表格式,请不要使用此文档所述的方法
其它规则
- 每段数据的行数规则
分段报表、交叉表的每段数据的行数要大于最大分组的数据 - 分段、交叉表没有设置数据完整性字段如何展现
对于分段、交叉表如果没有设置数据完整性字段,则不能保证数据的完整性,会按照列式报表的方式展现和导出(即没有空白半页或者空白页) - 对于每段数据的数据量
行数列数<500030(初步估计) - 仅存在一个默认主数据集
在数据集定义时,默认第一个数据集为主数据集;包含海量数据的数据集有且仅有一个,并且要定义为主数据集 - 需要准确设置非数据区
为了保证柔性分段时数据计算的准确,必须保证每张报表的非数据(标题、表头)区明确指定,不能和数据区混在一起。 - 海量数据导出仅支持pdf、xls、xlsx、 xml电子表格、csv格式
其中pdf、xls格式会导出一个zip格式的压缩包,而csv、xlsx、xml电子表格会导出单一文件。
样例
海量数据报表初步定义
下面以一个24万条数据的列式报表为例,介绍如何定义一张海量数据报表。 将报表设置为分段报表
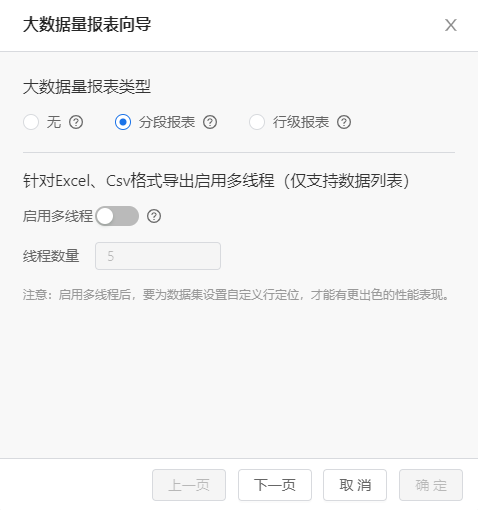
设置主数据集
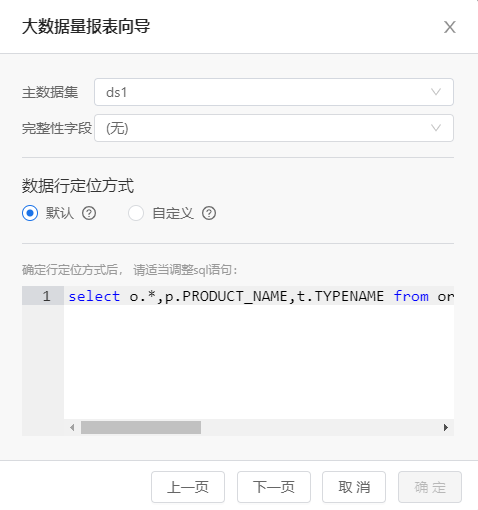
设置预计算总页数
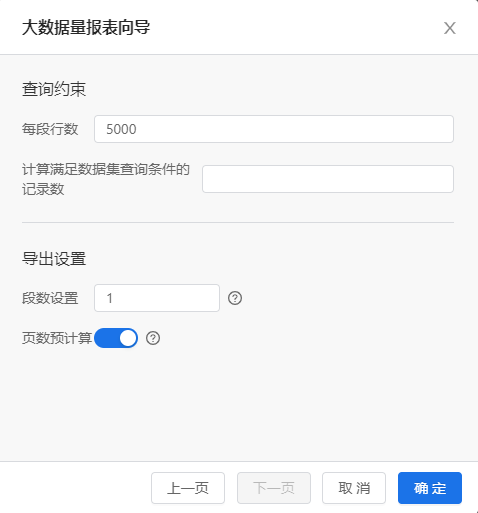
数据集设置计算满足条件的总记录数
数据集设置每段数据行数
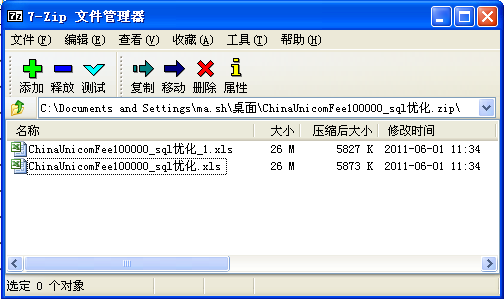
导出设置:设置几段数据导出一个文件,如下图所示,设置每十段数据生成一个文件后导出的zip文件
报表展现:下图为每页显示30条数据的结果

报表导出:下图为十万条数据,设置每十段数据生成一个文件后导出的zip文件。
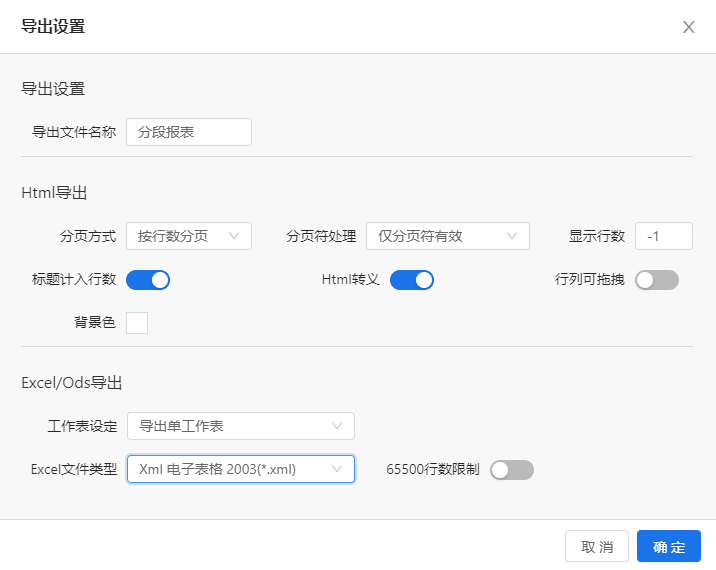
在UniEAP ReportV4.4版本以后,通过设置Excel导出格式的设置,也可以将Excel导出成一个完整的文件,设置方法如下:
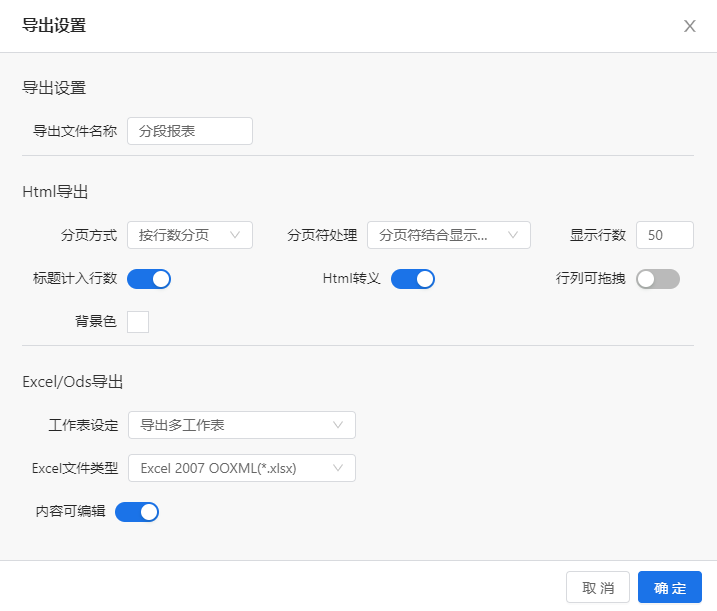
从UniEAP ReportV4.6版本开始,可以实现Excel2007导出格式的设置,它可以导出成一个完整的Excel2007文件,而不是一个Zip文件包,设置方法如下:
海量数据报表进一步优化
由于受到JDBC实现的影响,一些数据库提供的驱动分段取数的能力有限,使无法让达到更好的性能表现,下面介绍对海量数据报表的进一步优化。(注:本例仅适用于oracle数据库)
数据集设置自定义获取数据记录数的sql语句,数据行定位方式修改为‘自定义’如下图

修改数据集查询sql语句如下:
select * from ( select row_.*, rownum rownum_unwanted from (
SELECT * FROM BF_PAY_FEE_T_2) row_ where rownum <= $endRow ) where rownum_unwanted >= $startRow
其中$startRow代表当前数据段的起始位置,$endRow代表当前数据段的结束位置。
再次运行这张报表,导出excel时间可缩短为优化前的1/3左右。
大数据量行级报表
行级报表从UniEAP? Report V5.1版本开始支持。
方案简述
行级报表是为了解决报表数据量很大情况下内存占用过大,以及大数据量报表导出慢的问题。
支持的报表类型:
- 列表式报表
使用规则
支持报表类型
行级报表是为了解决报表数据量很大情况下内存占用过大以及导出较慢的问题,有一定的针对性,并不是UniEAP Report内可以定义的所有报表都支持该方法,支持的报表类型为:
- 列表式报表(数据列表)
超出本范围的报表格式,请不要使用此文档所述的方法
其它规则
- 行级报表数据区的单元格公式只支持select和get公式,select公式中不支持过滤条件及排序
- 不支持引用行级报表数据区的单元格进行计算
- 仅存在一个默认主数据集,包含大数据量的数据集有且仅有一个,并且要定义为主数据集
- 行级报表导出pdf、Word、xls格式会导出一个zip格式的压缩包,而csv、xlsx、xml电子表格会导出单一文件。
- 不支持多布局报表,只能有一个子布局
- 报表类型不能设置为填报
- 单元格不支持分页符属性
- 导出时单元格内容不支持自动换行属性
样例
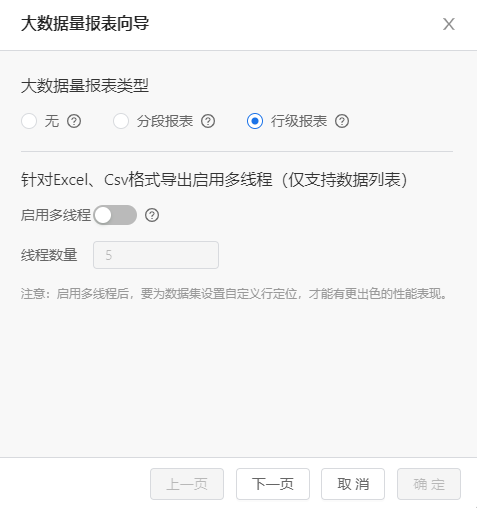
下面以一个100万条数据的列式报表为例,介绍如何定义一张行级报表。首先设置报表为行级报表,点击工具栏中大数据量报表设置图标,选择报表类型为“行级报表”:
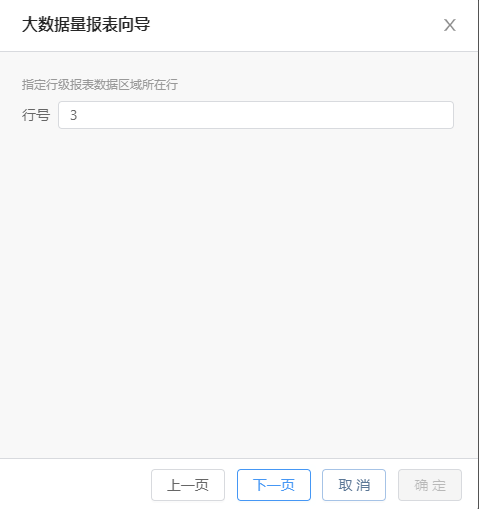
点击“Next”,指定行级报表数据区域所在行:
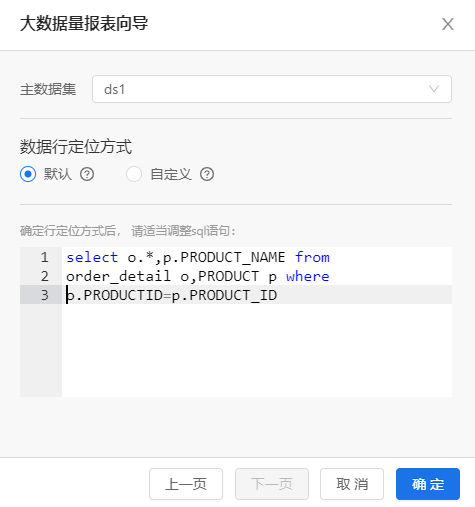
点击“Next”,设置数据行定位方式,默认方式为“默认”:
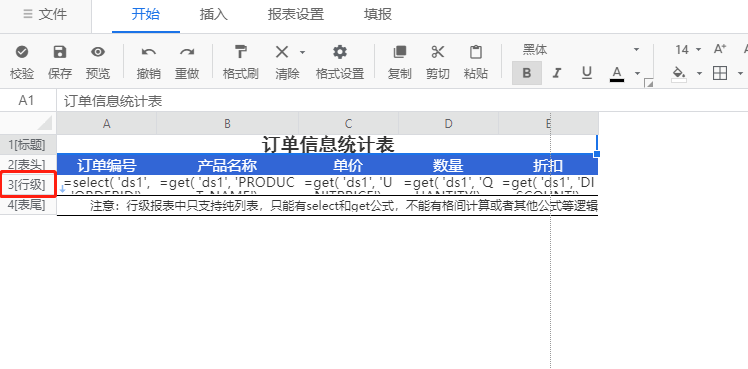
点击Finish完成行级报表设置,定义报表,如下图所示,指定为行级报表数据区域的行会显示行级报表的标识:
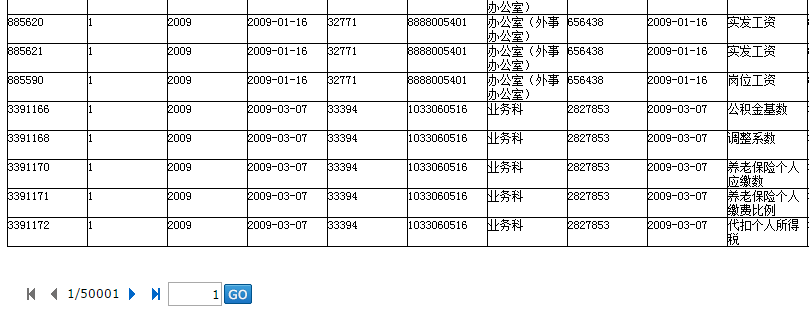
100万条数据,每页显示20行,展现结果如下图所示:
数据集行定位设置
由于受到JDBC实现的影响,一些数据库提供的驱动分段取数的能力有限,使无法让达到更好的性能表现,下面介绍对大数据量报表的进一步优化。(注:本例仅适用于oracle数据库)。
在大数据量设置向导中,选择报表类型为分段报表或行级报表,在设置主数据集界面中设置行定位方式,默认定位方式为默认(和数据集设置的SQL一致),这里数据行定位方式修改为‘自定义’如下图如下图所示:
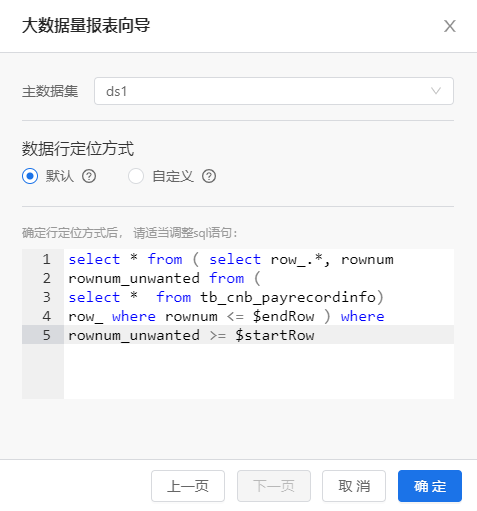
修改数据集查询sql语句如下:
select * from ( select row_.*, rownum rownum_unwanted from (
select * from tb_cnb_payrecordinfo) row_ where rownum <= $endRow ) where rownum_unwanted >= $startRow
其中$startRow代表当前数据段的起始位置,$endRow代表当前数据段的结束位置。
再次运行这张报表,导出excel时间可缩短为优化前的1/3左右。